Hi, I'm Sivaram GS.
A
Self-driven, quick starter, passionate Senior Data Science Engineer with a curious mind who enjoys solving a complex and challenging real-world problems.
About
- Senior Data Science Engineer with 9+ years of experience in building, fine-tuning, and deploying LLMs and ML systems, leading a team of six members. US patent holder with strong expertise in generative AI, model optimization, vector search, and delivering impactful presentations to C-suite leaders at Evertz. Proven track record as a Scrum Master with expertise in Agile based projects.
- Languages: Python, Pyspark.
- Databases: MySQL, PostgreSQL, PG_Vector, Pinecone, Neo4j, Elasticsearch, Redis.
- Platforms: AWS, Azure, Microsoft Fabric, Databricks, Snowflake, Spark, Kafka, Flink.
- Libraries: NumPy, Pandas, Scikit-learn, NLTK, Matplotlib, Plotly, MLflow, Zenml, Kedro, Aimlflow, Optuna.
- Frameworks: PyTorch, Langchain, Langraph, Chainlit, Streamlit, Logstash, Kibana, Grafana, Fast API.
- Collaborative Tools: Git, Jira, Confluence, Notion.
- Technologies: NLP, LLM, GenAI, MLOps, LLMOps, MCP, Power BI, Git, Docker, Kubernetes, Microservices.
Experience
Senior Data Science Engineer
- ❑ Integrated Glean for a unified AI-powered enterprise search and knowledge discovery.
- ❑ Built an MLOps module to track and alert on pre-trained model performance issues.
- ❑ Led & delivered evGPT (an OpenAI–powered LLM solution with fine-tuning and RAG).
- ❑ Delivered ML-driven analytics for NBA, MLB, and NHL, boosting engagement by 84%.
- ❑ Built real-time Easelive data pipelines, reducing report generation time by 90%.
- ❑ Sphere-headed deployments of Evertz’s inSITE (a big data analytics) for global clients.
April 2020 - Present | Bengaluru, India

Software Engineer 1
- ❑ Improved data quality and built analytics for Dell’s Digital Lifecare platform.
- ❑ Containerized the Dell EMC Solutions Enabler product, reducing OS image size by 70%.
- ❑ Hold US Patent-11256553 Intelligent System to Prioritize Servers for Envisaged Requests.
June 2017 - March 2020 | Bengaluru, India

Engineer
- ❑ Designed and delivered a Video on Demand non-linear delivery workflow for Comcast.
- ❑ Enabled full ad insertion in content packaging and reduced operators’ time by 60%.
- ❑ Configured and Deployed File based Media Asset Management Playout systems.
July 2016 - June 2017 | Bengaluru, India
Projects
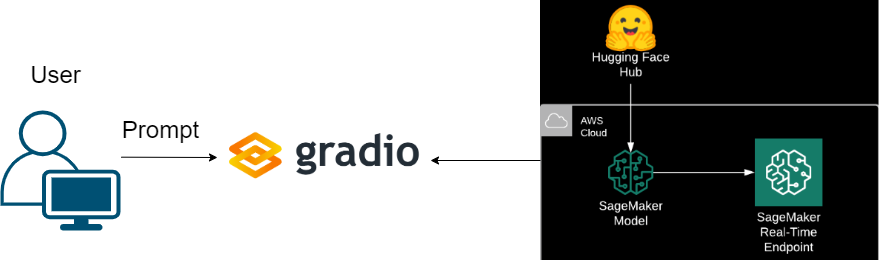
Inference of LaMini with Amazon SageMaker using Hugging Face DLC
Project
- Tools:LaMini-T5-738M, Amazon Sagemaker, Hugging Face Deep Learning Container, Python 3.10 , Pytorch, Gradio
- Created a domain in Amazon Sagemaker for managing and organizing the machine learning workloads.
- Created a notebook instance (ml.c5.2xlarge) which is pre-installed with popular libraries for machine learning and to keep the compute environment secure for LaMini-T5-738M.
- Installed the required libraies and deployed the model with instance_type="ml.g4dn.xlarge" using Hugging Face Deep Learning Container.
- Noted the Endpoint created under the inference section in Amazon sagemaker.
- Tuned the model with hyperparameter payload and integrated the sagemaker endpoint with a gradio.
- Launched the gradio app with a public URL for LaMini-T5-738M text2text-generation task inference.
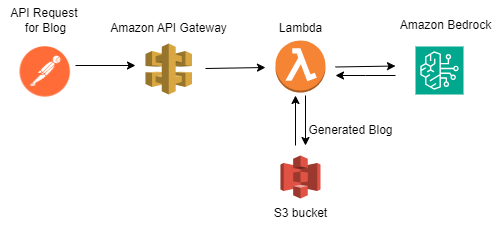
Serverless Blog Generation with Titan Model Using Bedrock in Lambda
Project
- Tools:Postman, Amazon API Gateway, AWS Lambda, Titan Text G1 Express Model , Amazon Bedrock, S3 Bucket, Cloudwatch
- Requested and got the access granted for Titan Text G1 Express Model in Amazon Bedrock.
- Noted model id and API request for Titan Text G1 Express in Amazon Bedrock.
- Created a API Gateway to trigger AWS lambda function and added route to make a POST API request.
- Written the python code to invoke Titan Text G1 Express model for blog generation of user topic.
- Made a POST API request from POSTMAN to Amazon API gateway endpoint to trigger the AWS lambda.
- Monitored the cloudwatch logs and saved the generated blog as a text file in S3 bucket.
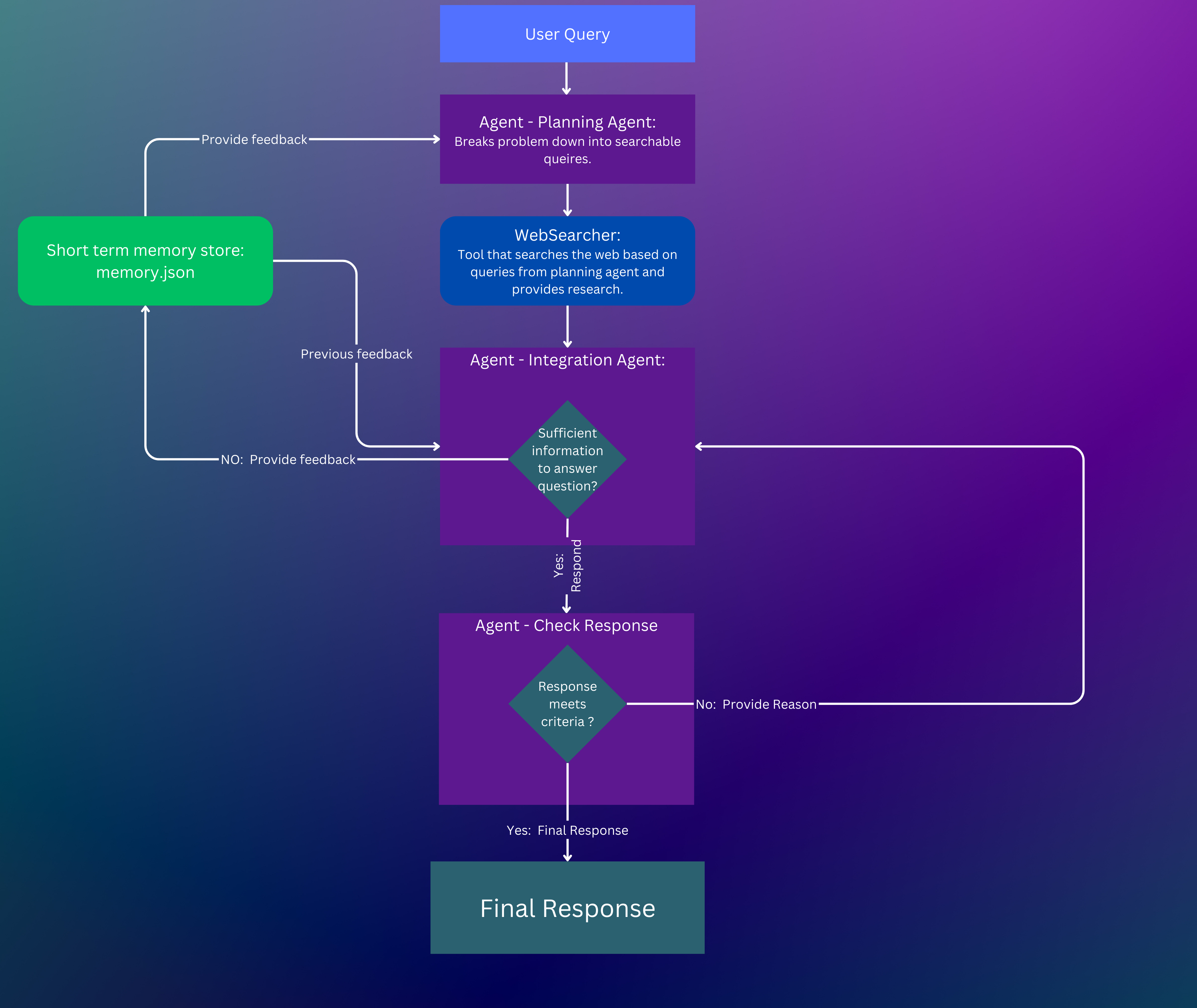
Custom WebSearch LLM Agent with Llama3 Instruct 8B Using Ollama
Project
- Tools: Llama3 Instruct 8B llm, Ollama, Serper Google Search API, Python 3.10
- Pulled llama3 instruct 8B fine-tuned LLM in ollama (framework to run llm models locally)
- Used serper as the primary tool for the search engine query intened for google search.
- Created planning agent to take user custom query as input and generate searchable queries.
- Created Integration agent to validate planning agent output and make a google search.
- Integration agent visited the sites and scraped the best pages to compile a response.
- Made a quality assessment on the response compiled and generated the final response if criteria met.
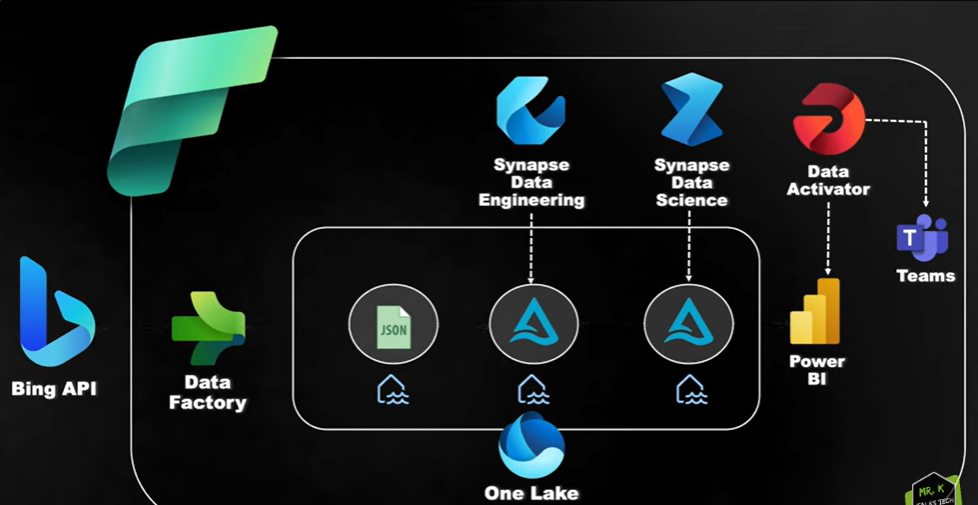
Sentiment Analysis on Bing News Data Using Microsft Fabric
Project
- Tools: Azure Bing Search V7 API, Fabric Data Factory, Synapse Data Engineering, Synapse Analytics, PowerBi, Data Activator, Reflex.
- Ingested data from Bing V7 API using Data Factory copydata activity.
- Transformated data to a curated Delta Table with incremental loading.
- Done Sentiment Analysis on the news and classified it as Positive / Negative / Neutral/ Mixed.
- Used DAX queries in PowerBi to create new measures and configured alerts using Data Activator Relex.
- Tested the complete flow and reviewed pipeline run results in Monitoring Hub.
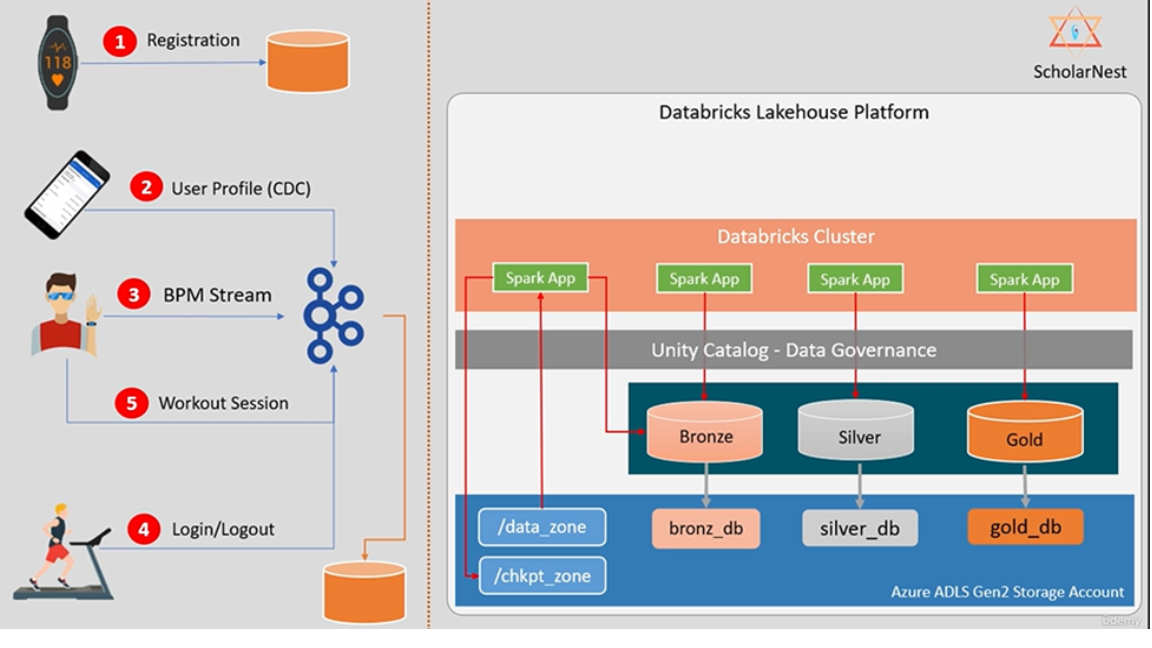
Stream Processing in Databricks Lakehouse with Unity Catalog
Project
- Tools: Azure ADLS Gen2, Databricks, Unity Catalog, Azure Devops, Key Vault.
- Created storage containers in ADLS Gen2 to store metadata, managed and unmanaged tables.
- Supported Batch and Streaming Worklows to ingest data.
- Designed and Implemented a secure Lakehouse Platform with Unity Catalog.
- Generated Workout BPM and Gym summary Datasets for analytics.
- Automated deployment pipeline in Azure Devops.
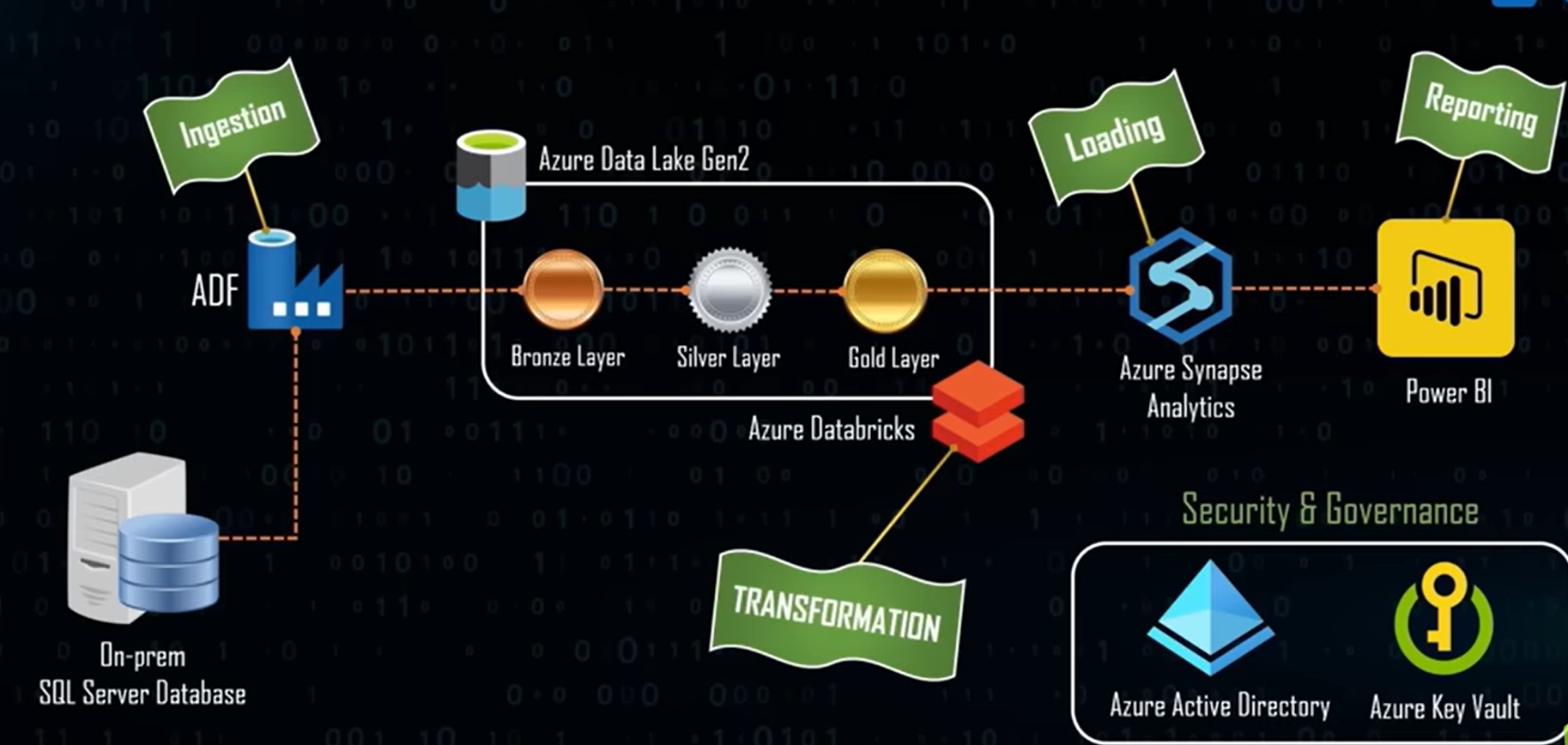
End to End Azure Data Engineering Real-Time Project
Project
- Tools: Azure Data Factory, ADLS Gen2, Key Vault, Databricks, Synapse Analytics, PowerBi, Active Directory.
- Started with data ingestion from on premises SSMS, into the Azure environment. Utilized Azure Data Factory for orchestrating and automating this process.
- Used Azure databricks to transform the RAW data.
- Used Azure Synapse Analytics to load the clean data (gold tables).
- Used PowerBi Analytics to create an interactive dashboard.
- Integrated Azure Active Directory with key-vault for user authentication and authorization.

Generative Adversial Network for Fashion Mnist with Tensorflow
Project
- Tools: Fashion Mnist Dataset 3.0.1, Tensorflow 2.16
- Preprocessed the dataset by scaling images through caching, shuffling, batching, and prefetching.
- Built the Generator that transforms random noise into realistic fashion images.
- Built the Discriminator that distinguishes generated fake fashion images from real images.
- Trained the GAN Model for 100 Epoch through backpropagation on Generator and Discriminator.
- Reviewed the Model Performance by plotting discriminator and generator losses for 100 epochs.
patent
Intelligent system to prioritize servers for envisaged requests
- Patent number: 11256553
- Date of Patent: Feb 22, 2022
- A workload manager uses on-band and off-band metrics to select a host server in a cluster to handle a connection request. The on-band metrics include CPU usage, memory usage, and vulnerability metrics. The off-band metrics include hardware component error logs. Utilization and vulnerability scores are calculated for each host server from the on-band metrics. A reliability score is calculated for each host server from the off-band metrics. A health score for each host server is calculated from the vulnerability and reliability scores. The health score is used to exclude unhealthy host servers from consideration. A priority score is calculated for each host server from the utilization, vulnerability, and reliability scores. The host server that has not been excluded and has the greatest priority score is selected to handle the connection request.
Certifications







Education
Liverpool John Moores University
Liverpool, United Kingdom
Degree: Master of Science in Data Science
- Data Engineering
- Machine Learning
- Deep Learning
- Computer Vision
- Natural Language Processing
Relevant Courseworks:
Chennai, India
Degree: Bachelor of Engineering in CS
- Data Structures and Algorithms
- Database Management Systems
- Operating Systems
- System Design
- Computer Networking
Relevant Courseworks: